Pas de Big Bang au Cern sur le cloud, mais une approche hybride
Le prestigieux laboratoire européen de recherche nucléaire adopte progressivement des technologies cloud au sein de ses opérations, notamment pour gérer les visites ou réconcilier des sources de données.

Pas de Big Bang au Cern sur le cloud
Le Conseil européen pour la recherche nucléaire, le Cern, est un des plus importants laboiraires de physique au monde. S'il jouit d'une grande renommée internationale, c'est notamment parce qu'il héberge le LHC, un accélérateur de particules.
Cette machinerie sous-terraine se compose notamment d'un tunnel de 27 kilomètres de longueur s'étirant entre la France et la Suisse. Grâce au LHC ou Large Hadron Collider, le Cern tente de percer les mystères du big bang.
Du Cloud pour un système de réservation à durée limitée
En revanche, en ce qui concerne l'adoption des technologies Cloud, la stratégie retenue est celle des petits pas et d'une infrastructure hybride. Le premier usage cloud au Cern portait ainsi sur une application destinée à traiter les inscriptions à son évènement Cern Open Days, un week-end dédié à la visite des installations.
Un maximum de 90.000 personnes pouvait être accueilli à cette occasion. Et compte tenu de la configuration de ses infrastructures, le Cern devait disposer d'un système de réservation performant afin de gérer les flux de visiteurs sur les différents sites d'accueil du public.
Or, il s'avérait complexe d'estimer en amont la charge applicative d'un tel outil. Cette application constituait donc un cas d'usage tout trouvé pour expérimenter le cloud, en l'occurrence la plateforme Oracle Cloud Infrastructure, ou OCI. Le système devait en effet pouvoir rapidement monter en charge.

Guide Défis d’un nouveau monde « Dette technique et legacy »
La scalabilité était donc un des premiers facteurs de choix, précise ainsi lors d’un webinar Oracle Sébastien Masson, administrateur base de données (DBA) au Cern. « C'était un critère fondamental », insiste-t-il, tout comme l'efficacité du déploiement. Quelques actions, puis par la suite des API, permettent d'accélérer des déploiements sur le cloud.
Mais si le cloud se prêtait aussi à ce cas d'usage, c'est car l'application avait une durée de vie limitée et que la base de données devait être accessible depuis tous les sites du Cern. « Le projet comportait aussi une dimension de challenge en nous permettant de débuter de premiers déploiements sur le cloud », confie le DBA.
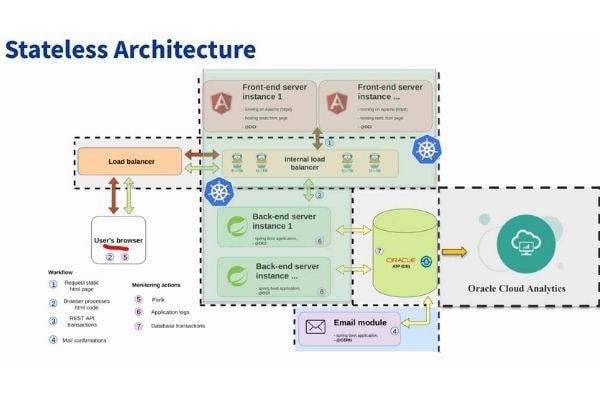
Une architecture stateless et de l'autoscaling pour l'agilité
Pour l'expert du Cern, une migration « en mode big bang" du cloud n'est tout simplement pas envisageable. Une démarche au contraire itérative permet aux équipes de se familiariser avec ces technologies et leur utilisation.
Pour développer son système de réservation, le Cern s'est donc appuyé sur une architecture dite « stateless », c'est-à-dire dont les composants sont indépendants (serveurs Web, back-end, base de données...).
cern
Il est alors possible de scaler indépendamment chaque composant, par exemple les serveurs Web en cas d'affluence des visiteurs sur la page de réservation. Pour répondre à un pic de trafic, il suffisait d'ajouter des instances Apache. Ce mode de consommation en fonction des besoins permet ainsi, pour la base de données, de consommer plus ou moins de stockage ou de CPU.
Une fonctionnalité d'autoscaling offre par ailleurs la possibilité de laisser la base de données automatiquement solliciter plus de ressources. Les équipes du Cern ont d'ailleurs eu recours à cette fonction, multipliant par dix la capacité de stockage allouée au départ. Cette exploitation se démarque nettement de l'approche adoptée dans les environnements on-premise.
La pratique consiste alors à dimensionner en fonction de la charge maximum attendue, ce qui revient souvent à payer des ressources IT au final sous-exploitées. Les opérations IT du Cern ont tiré profit d'un autre avantage du cloud, à savoir l'automatisation de différentes tâches d'administration, comme le patching.
Latence réseau et souveraineté des données maîtrisées
Après ce premier cas d'usage du cloud Oracle, le centre de recherche a mis en production d'autres scénarios. Le Cern exploite désormais Autonomous Datawarehouse, un entrepôt de données dans le cloud. Ce service intervient pour réconcilier plusieurs sources de données, structurées et non structurées.
Le Cern peut ainsi croiser les données de nombreux capteurs de l'accélérateur de particules pour fournir des informations aux opérateurs du centre de contrôle. Température, pression, alimentation électrique... l'IoT collecte d'importants volumes de Data. Le Cloud permet en outre au Cern de disposer d'un plan de reprise d'activité (PRA), avec donc des bases de données répliquées et disponibles simultanément sur deux sites distants.
Le Cern ne mise cependant pas intégralement sur des services de cloud public. Le Conseil européen a aussi souscrit au modèle du « cloud at customer » d'Oracle. Il dispose ainsi d'une infrastructure Exadata au sein de son propre datacenter, derrière ses firewalls dans une approche hybride. Le déploiement de ce cloud interne est en cours actuellement au Cern.
L'intérêt ? « La latence réseau, qui peut parfois être un frein au déploiement d'applications critiques dans le cloud, est levé. L'aspect de la souveraineté des données est aussi résolu », conclut Sébastien Masson. Oracle administre en effet l'équipement Exadata, dont l'hyperviseur et le patching, sans cependant avoir accès aux données.




