SNCF convainc en interne sur les atouts de l’IA par l’explicabilité
La factory Data & IA de la SNCF a développé un modèle prédictif de machine learning pour aider les approvisionneurs de la branche Matériel

Technicentre SNCF
La factory Data & IA de la SNCF a développé un modèle prédictif de machine learning pour aider les approvisionneurs de la branche Matériel dans leurs prises de décisions. Chaque résultat est expliqué à l’utilisateur pour permettre l’adoption.
Plusieurs facteurs contribuent à l’acceptation de l’intelligence artificielle par les métiers au sein des organisations. L’acculturation est un de ces leviers, comme l’est également la confiance, ou encore l’explicabilité.
A la SNCF, l’explicabilité des résultats des algorithmes mis en production constitue d’ailleurs un axe de travail stratégique pour la factory Data & IA d’ITnovem, la filiale technologique du groupe français.
A lire aussi : Chez SNCF Connect & Tech, les directeurs UX et technologies parlent de la sécurité d’une seule voix
L’explicabilité devenue une nécessité pour transformer
“L’explicabilité est presque devenue une nécessité pour nous. Nous travaillons avec des personnes qui connaissent le métier, mais pas le machine learning. Si un modèle d’IA opère comme une boîte noire, le métier n’est pas convaincu par le résultat qu’il lui propose”, témoignait lors du salon Big Data Amine Souiki, senior data scientist et data engineer.
Lors des projets qu’elle mène pour les entités de l’entreprise, la factory définit donc les solutions les plus pertinentes pour expliquer au métier concerné les prédictions d’un algorithme de machine learning.
Cette méthodologie a également été mise en œuvre dans le cadre de la conception d’un modèle destiné à prédire les risques de surstock pour l’activité Matériel de la SNCF. Celle-ci gère les approvisionnements en pièces des technicentres. Ces achats constituent un poste de dépenses conséquent pour le transporteur.
En 2020, la DSI de SNCF Matériel a souhaité optimiser sa gestion des stocks en limitant autant que possible les surstocks. La factory Data & IA d’ITnovem a été missionnée pour ce projet.
Le besoin portait sur la conception d’un outil d’IA de prédiction des risques de surstock. La solution visait à “fournir au sein de l’ERP des approvisionneurs des prédictions toutes les semaines pour les aider dans leur prise de décision”, précise Camille Samson, directrice de mission Data à la SNCF.
Le prédictif au service de la gestion des stocks
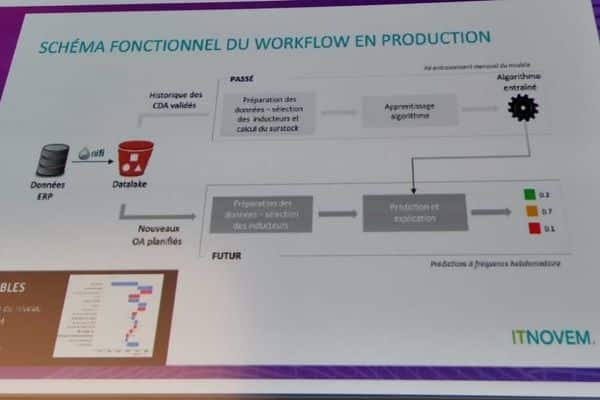
Schema SNCF IA
Classiquement pour un projet de ML, la première étape a pris la forme d’un PoC débutant par la construction d’un dataset. Ont été définies la variable expliquée du modèle (le surstock) et les différentes variables explicatives (ou features).
Le surstock a été catégorisé en trois niveaux - de non-critique à critique. Pour établir cette classification, l’entreprise a exploité différentes données sources. Parmi celles-ci, le montant des ordres d’achat, l’historique de planification, et des référentiels sur les articles et les technicentres.
La tâche des data scientists revient alors à analyser “la corrélation entre les différentes variables explicatives et la variable cible afin de se limiter aux variables les plus influentes pour construire un algorithme de machine learning le plus pertinent possible”, indique Amine Souiki.
Ces variables sélectionnées, l’équipe a pu s’atteler à l’étape de conception du modèle. Plusieurs algorithmes distincts ont été testés pour comparer leurs performances et identifier le plus adapté.
C’est finalement un algorithme de type gradient boosting, “très populaire lorsqu’on travaille avec des données structurées”, qui a été retenu pour fournir les prédictions utiles au métier de l’approvisionnement.
Une architecture cloud et industrialisée
En phase de PoC, la preuve de valeur du modèle mis au point a été démontrée. “Nous obtenions une diminution d’un facteur 8 du coût estimé du surstock tout en respectant les contraintes”, témoigne le data scientist senior.
Grâce à ces résultats, la data factory a donc pu déclencher l’étape d’industrialisation. Celle-ci repose notamment sur la conception d’une architecture de traitement des données et de calcul des prédictions.
Les données sont extraites de l’ERP chaque semaine et transférées sur un data lake cloud S3 (AWS). Une étape de quality management intervient dans le processus afin de nettoyer les données.
Le modèle d’IA est réentraîné chaque mois. Quant à la phase d’inférence, elle est réalisée de manière hebdomadaire. Pour fournir cet outil d’aide à la décision aux approvisionneurs, ITnovem exploite différents services cloud sur AWS.
“L’algorithme entraîné, les hyper-paramètres et les métriques de performance sont stockés et versionnés grâce à MLflow, intégré à Databricks”, détaille Amine Souiki. Quant aux résultats du modèle, ils sont restitués au sein d’une application Web.
Le métier accède aux prédictions, ainsi qu’à l’explication de cette décision algorithmique sous la forme d’un fichier PNG. L’utilisateur métier est informé de la nature des variables qui ont le plus pesé dans le résultat.
Une DSI facilitatrice et un métier impliqué de bout-en-bout
Pour Camille Samson, la qualité de la solution technique ne suffit pas cependant à expliquer la réussite de ce projet, qui s’est traduit par un véritable changement au niveau des processus opérationnels et pour les collaborateurs, “pas forcément sensibles à l’IA”.
Parmi les facteurs clés de succès, la directrice de mission cite en premier lieu la constitution d’une “équipe solide et tripartite composée de la DSI, du métier et d’ITnovem comme expert Data.”
De plus, la “DSI s’est positionnée en clé de voûte du projet. Cela a été clé pour nous mettre en relation avec le métier afin d’être véritablement partie prenante du dispositif”. Par ailleurs, le métier a été “intégré tout au long de la chaîne, à chaque étape du projet”.
Cette implication du métier a permis in fine la fourniture d’un “outil sur-mesure et utilisé par les approvisionneurs dans leur quotidien”, insiste Camille Samson. En termes de méthodologie enfin, l’équipe Data a procédé à un “lotissement du projet, avec des objectifs précis à chaque étape.”
Sur l’explicabilité, différents ateliers réunissant le métier ont été organisés dans le but de déterminer le bon type de graphique justifiant le résultat de l’algorithme de prédiction, favorisant ainsi la confiance tout en levant les freins à l’adoption.




