Leboncoin : récit d'une transition vers le Data Mesh
Le site de petites annonces a bien grandi depuis sa création en 2006, comme sa production de données et ses usages. La plateforme Data a été transformée à plusieurs reprises et s’oriente désormais vers un modèle Data Mesh.

data-mesh-leboncoin
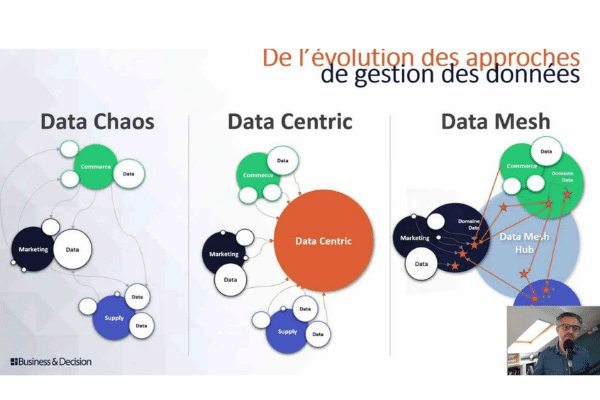
Dans l’univers de la Data, les concepts sont nombreux et mouvants. Rien n’est en effet figé, notamment en termes d’organisation, de gouvernance ou d’architecture, à l’image des usages qui ne cessent d’évoluer. Se développe ainsi un nouveau concept, le Data Mesh, élaboré par Zhamak Dehghani.
Le Data Mesh ne part pas d’une feuille blanche. Il marque cependant une inflexion par rapport à une tendance antérieure à la centralisation des données. Dehghani définit ainsi le Data Mesh comme une approche socio-technique.
Data Mesh : de l’avènement de la décentralisation
Elle est d’abord “totalement décentralisée et permettant de manager et d’accéder aux données à des fins analytiques et surtout à l’échelle”, résume Mick Levy. Le directeur de l’innovation business pour Business & Decision s’exprimait à l’occasion d’un webinar du Salon de la Data.
data-mesh1
Chez Leboncoin, un site lancé en France en 2006, la transition vers une approche de type Data Mesh, a naturellement été très progressive. Elle n’est d’ailleurs pas complète. Le data engineering sur le site e-commerce, dont le périmètre a explosé depuis sa création, est un chantier continu depuis 15 ans.
L’entreprise emploie aujourd’hui près de 1500 personnes environ, dont 500 au sein de l’équipe tech. Les évolutions d’architecture ont été tirées par la forte croissance de la société. En 2012, la stack Data, c’était ainsi un script shell calculant chaque jour des KPI intégrés ensuite dans le corps d’un email destiné au marketing.
Ces données étaient alors copiées dans un Excel à 12.000 onglets, le format idéal pour de l’analyse. Si le script répondait à un usage, il s’était toutefois transformé au fil des années “en un monstre, un plat de spaghettis indigeste”, reconnaît Simon Maurin, Lead Architect pour Leboncoin.
Le monstre a donc été “tué”, pour laisser place à une stack de business intelligence avec une brique d’ETL et du stockage dans une base datawarehouse. Au-dessus, une application web de BI permettait de générer tableaux croisés dynamiques et dashboards. Le modèle présentait cependant des limites, accentuées par une montée en charge rapide : faible évolutivité, instabilité de la plateforme, etc.
Une plateforme Data pour préparer l’avenir
Un “second monstre” était né, commente Simon Maurin, qui présentait ce REX lors du Salon de la Data. Entre 2015 et 2018 est constituée une data plateforme tenant compte d’exigences de scaling, d’élasticité, de résilience. Elle devait aussi être capable de s’affranchir des limites physiques d’infrastructure.
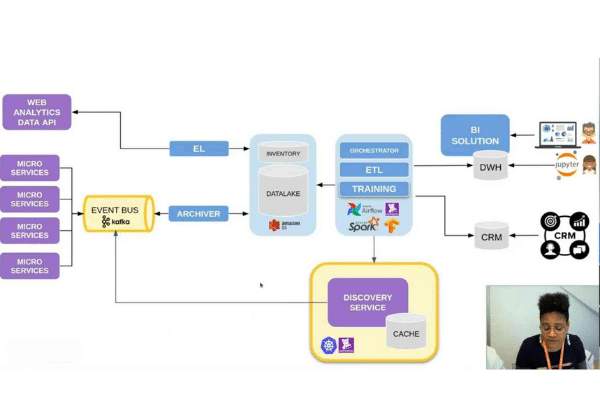
Pour la construire, l’équipe IT fait donc appel au cloud, découple son architecture, avec notamment un data lake. La finalité : c’est le développement des produits data driven, détaille Stéphanie Baltus, Lead Data Engineer pour Leboncoin. Airflow est en outre déployé pour la gestion des pipelines de données et l'exécution de workflows. Pour le monitoring, l’entreprise s’appuie sur Datadog.
data-mesh3
La nouvelle architecture consiste donc à récupérer la donnée des différentes sources pour la stocker brute dans le data lake. Pour le décisionnel, est déployée une nouvelle solution de BI, complétée par des notebooks Jupyter pour les data scientists. Le stockage distribué est enfin géré via Amazon Redshift. La data plateforme a été mise à contribution pour fournir un premier produit data driven : un CRM pour les télévendeurs. Les données ont permis aussi la personnalisation de l’emailing.
“Ce sont des cas d’usage assez simples ne nécessitant pas nécessairement de l’intelligence artificielle, mais qui permettent de créer directement de la valeur sur la donnée”, souligne le Lead Architect du site. En 2017, des changements au niveau de l’organisation enclenchent de nouvelles évolutions.
Les équipes, auparavant organisées par départements et spécialités, basculent dans un modèle en feature teams, des petites équipes pluridisciplinaires. A chacune des domaines métiers dédiés. Cette organisation implique des changements d’architecture avec des applications monolithiques refondues en microservices.
Des feature teams owners sur des domaines data
Première décision dans ce cadre : l’ownership de la production de données revient à l’équipe en charge du domaine associé. “Nous commençons alors à mettre un doigt, sans le savoir et sans le nommer, dans l’approche data mesh”, note Simon Maurin. En 2018, c’est la direction qui vient taper à la porte pour pousser au-delà la dimension data driven avec l’introduction de l’IA.
L’IT ajoute donc à sa stack des composants permettant notamment de faire du training de modèle de ML et de proposer de premières applications, comme de la recommandation sur le site. Mais la croissance des besoins en IA se heurte alors à un manque de ressources de data ingénieurs, restés en central dans l’organisation. En résulte un allongement du développement des projets data.
C’est à ce stade que l’entreprise prend clairement une orientation vers le Data Mesh afin de lui permettre un passage à l’échelle. Cela se traduit par une décentralisation d’une partie de la gestion des données auprès des feature teams. Des compétences de data engineering intègrent dans ce cadre ces équipes.
D’autres compétences ont pour mission de proposer des infrastructures data en mode plateforme “faciles à consommer par les autres développeurs et facilitant l’usage de la plateforme au sein des différentes équipes.” Les développeurs disposent en outre d’un catalogue de l’ensemble des sources de données existantes et des produits Data, accélérant la création de nouveaux produits.
Le data engineering : des compétences mutualisées
“Nous avons bien avancé sur le MLOps. Nous avons adapté toute la CI/CD pour y ajouter les notions de modèle, de dataset et d’expérimentation. A aussi été mis en place un feature store permettant de mettre en commun les différents KPI servant à l'entraînement des modèles”, détaillent les experts techniques.
Ces derniers se déclarent satisfaits du fonctionnement mis en place. Reste à présent à industrialiser le passage à l’échelle. Une des solutions consisterait à recruter massivement des data ingénieurs distribués au sein des feature teams. Pour des raisons de coût, le scénario n’est pas réaliste. L’approche retenue privilégie une convergence des compétences via “une pollinisation des compétences” en dotant les ingénieurs logiciels de compétences en ingénierie data.
Le pôle IT s’efforce donc de former l’ensemble des équipes à des problématiques comme le CI/CD ou les systèmes distribués et de stockage. Cela passe par le recours à du pair programming, à la constitution de communautés et au partage de connaissances, par exemple.
A terme, un développeur back-end devra ainsi être en mesure de concevoir un pipeline data sans le support d’un data ingénieur. La formation dispensée en interne est un moyen de mutualiser les compétences. Les ingénieurs existants seront formés en ce sens, comme les nouvelles recrues. C’est aussi une façon de faire face à la pénurie de profils data, et en particulier de data ingénieurs.




