Quel impact environnemental pour l’IA générative ?
[L’enquête] Le monde de l’IA générative est aujourd’hui écartelé entre les bénéfices apportés par cette technologie et son coût environnemental. Mais comment se calcule ce dernier ?


Enquete_impact environnemental pour lIA générative
Le monde de l’IA générative est aujourd’hui écartelé entre les bénéfices apportés par cette technologie et son coût environnemental. Mais comment se calcule ce dernier ?
L’intelligence artificielle, et plus particulièrement l’IA générative, est dans l’esprit de toutes les DSI, business units et directions générales. Dans une étude parue en 2023, le cabinet McKinsey a identifié 63 cas d'usage de l'IA générative couvrant 16 fonctions commerciales qui pourraient générer une valeur totale de l'ordre de 2 600 à 4 400 milliards de dollars en avantages économiques par an lorsqu'ils sont appliqués à l'ensemble des secteurs d'activité.
Toujours selon McKinsey, l'IA générative pourrait avoir un impact sur la plupart des fonctions de l'entreprise. Toutefois, quatre fonctions (opérations clients, marketing / ventes, ingénierie logicielle et recherche & développement - représenteraient à elles seules environ 75 % de la valeur annuelle totale des cas d'usage de l'IA générative.
Dans le même temps, l’Agence internationale de l’énergie (International Energy Agency / IEA) a lancé un avertissement dans son rapport 2024 intitulé « Electricity - Analysis and forecast to 2026 » : l'agence prévoit une augmentation de plus de 30 % de la demande énergétique liée à l’intelligence artificielle et aux cryptomonnaies d'ici 2026.
Selon l’Agence internationale de l’énergie, les centres de données consacrés à l'IA et au minage de cryptomonnaies ont consommé 460 TWh en 2022, soit près de 2 % de la demande mondiale. Cependant, toujours selon le rapport de l'AIE, cette consommation pourrait dépasser les 1 000 TWh dans les deux prochaines années (c’est-à-dire d’ici 2026), ce qui correspondrait à la consommation d’un pays comme le Japon.

Mesure : pour une même opération, avec le même matériel, des résultats très différents
Dans ce contexte, de nombreux chercheurs, experts et scientifiques de tous horizons se sont mis au travail pour tenter d’y voir plus clair sur le fonctionnement des grands modèles de langage (Large language models / LLM) qui constituent le « moteur » de l’IA générative.
« Si vous voulez mesurer ce que consomme un LLM, force est de constater que l’IA hérite du numérique : pour une même opération, avec le même matériel, on obtient des résultats très différents. Il n’existe aujourd’hui aucun standard. Les mesures sont différentes : par exemple, certaines comptent la consommation du CPU à partir du TDP (thermal design power) tandis que d’autres prennent le déclaratif de l’utilisateur », explique Ana Semedo, Managing Partner chez ILExpansions, Responsable IA au sein de l’institut G9+ et membre de Planet Tech’Care (Numeum).
Heureusement, un certain nombre d’études plus précises émergent, nous permettant de mieux comprendre les consommations énergétiques et l’impact carbone induits par la phase « inférence » des grands modèles de langage. C’est le cas notamment de l’étude “Power Hungry Processing: Watts Driving the Cost of AI Deployment?” menée par Sasha Luccioni et Yacine Jernite, respectivement Climate Lead & AI Researcher et Machine Learning & Society Lead chez Hugging Face, et Emma Strubell, Assistant Professor au sein de la Carnegie Mellon University.
Cette étude, menée sur 10 tâches différentes (classification, génération de texte et d’image...), 30 jeux de données et 88 modèles d’IA (modèles mono-tâche et multitâche), mesure le coût de déploiement, c’est-à-dire la quantité de CO2 émise lorsque 1 000 inférences (requêtes) sont effectuées. Le premier constat est sans appel : les tâches génératives (texte, résumé, image...) sont 10 à 100 fois plus émettrices de CO2 que les tâches de classification.
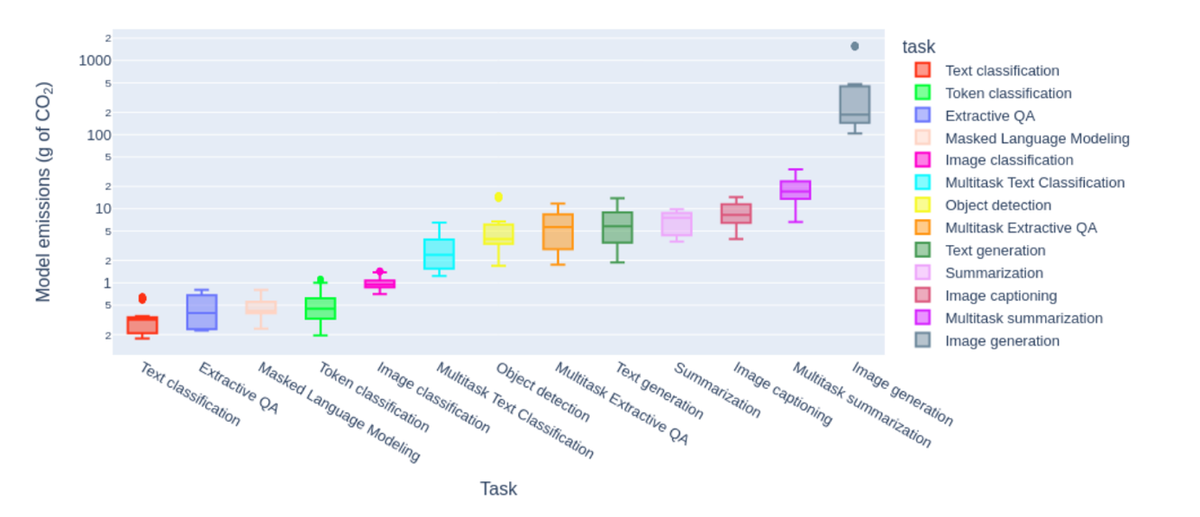
Emissions CO2
Les tâches examinées et la quantité moyenne d'émissions de CO2 (en g) qu'elles produisent pour 1 000 requêtes. N.B. L'axe des ordonnées est en échelle logarithmique.
Autre enseignement de cette étude : l’utilisation de modèles polyvalents pour réaliser des tâches spécifiques, comme la classification, est plus énergivore que l’emploi de modèles dédiés à ces tâches. Autrement dit, rien de sert de se servir d’un LLM multitâche pour réaliser une tâche bien précise comme la réponse à des questions par un chatbot. Le surcroit d’énergie peut être d’un facteur 30, selon le jeu de données impliqué.
Phase d’entrainement des LLM : d’importants écarts également
Et si l’on remonte encore plus en amont, c’est-à-dire pendant la phase d’entrainement des grands modèles de langage, les différences sont, là aussi, criantes. « Sur la partie entrainement, les rapports vont de 1 à 20. Si l’on compare Bloom et GPT-3, on voit que les deux LLM ont été entrainés respectivement sur 173 et 175 milliards de données. Mais la consommation pour Bloom a été de 433 MWh et de 1 287 MWh pour GPT-3. Par la suite, en prenant le PUE des datacenters ayant servi à cet entrainement et les émissions équivalent CO2 de l’énergie des pays où ils se situent, le volume émis par Bloom est de 30 tonnes de CO2 et de 552 tonnes pour GPT-3 », commente Ana Semedo.
Cet écart est corroboré par de nombreuses autres études, dont celle de l’Université de Stanford, intitulée « Artificial Intelligence Index Report 2023: Introduction to the AI Index Report (2023) ». Dans le graphique ci-dessous, l’écart entre Bloom et GPT-3 est confirmé :
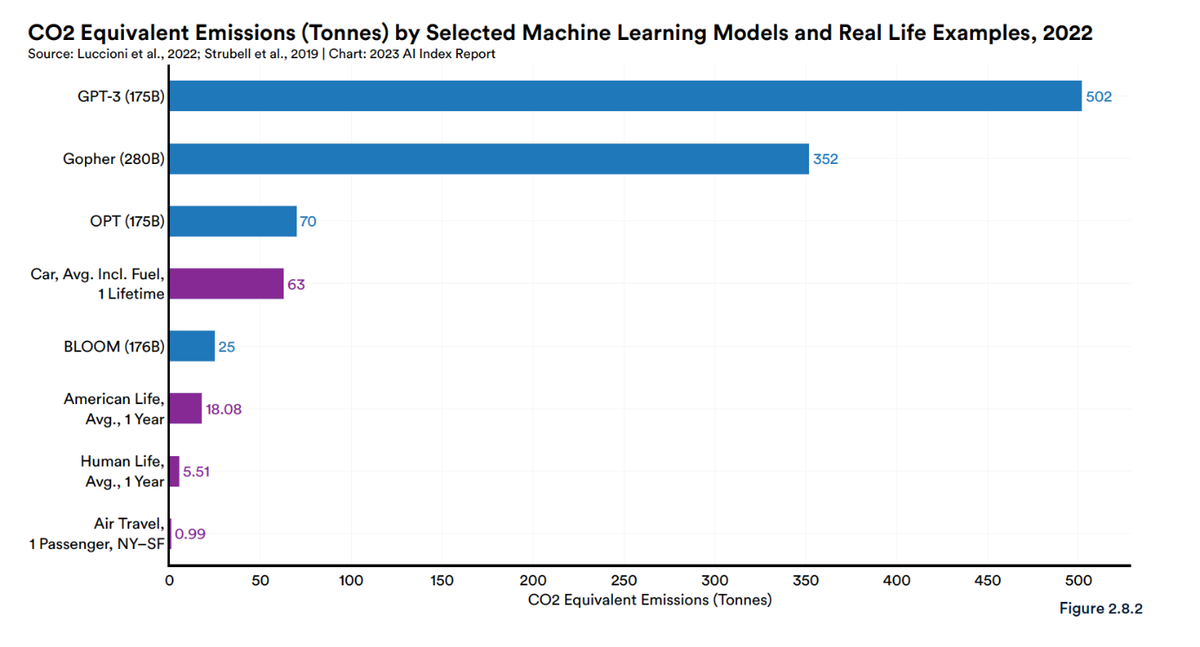
Artificial Intelligence Index Report 2023
© « Artificial Intelligence Index Report 2023: Introduction to the AI Index Report (2023) », Stanford University
Énergies 100% renouvelables, trajectoire net zero... Quelle stratégie adopter ?
Les principaux champions de l’IA générative, y compris en France, laissent le sujet en retrait, préférant mettre en avant l’innovation technologique et le développement économique apportés par leurs organisations. Ce qui n’empêche pas les géants de la tech d’avoir à se positionner. C’est alors souvent la carte des énergies renouvelables qui est jouée, comme on peut le voir notamment chez Google. « Google a pris des engagements très forts, à horizon 2030, de s’affranchir totalement des énergies fossiles. Dans notre rapport environnemental de 2023, pour l’exercice 2022, nous estimons être arrivés à 64% de cet objectif. Nous sommes à peu près aux deux tiers, c’est toujours le dernier tiers qui est le plus difficile à atteindre, mais tous nos investissements actuels nous permettent de croire que nous réaliserons cet objectif », déclare Floriane Fay, Responsable des affaires publiques et du développement durable chez Google, qui s’est exprimée lors d’une table ronde organisée conjointement le 12 mars dernier par le G9+, Planet Tech Care / Numeum, le Cigref et le Hub France IA.
Côté acteurs français, l’efficience de l’IA et sa compensation « green » sont également des sujets de premier plan. « Avec 300 data scientists qui travaillent pour nos clients, nous sommes très concernés par ces questions. Le groupe La Poste est d’ailleurs engagé vers une trajectoire net zero à horizon 2030. C’est un cadre qui n’est plus à mettre en place, c’est une stratégie qui est posée, il faut simplement que le temps de l’exécution se déroule », note Olivier Senot, Digital Innovation Officer de Docaposte, la filiale numérique du groupe, également présent lors de cette table ronde.
Mais pour Hugues Ferreboeuf, Membre du Conseil Consultatif de l’European Green Digital Coalition et Directeur de Projet au Shift Project, la véritable question que les entreprises doivent se poser est de savoir si l’IA doit être utilisée ou pas. « La consommation énergétique du numérique, qui augmentait de 5 à 6% par an, va probablement passer dans les années qui viennent à une augmentation de 8 ou 9% par an, ce qui signifie qu’elle va doubler en 7 à 8 ans. Le fait que l’IA se développe aussi vite actuellement me crée plus un sentiment d’insécurité que de confort », analyse-t-il.
Quant à Fabrice Bonnifet, Président du C3D et Directeur Développement Durable du Groupe Bouygues, il estime que la question centrale qu’il faut se poser est celle des usages et des mésusages : « La question est de savoir à quoi nous souhaitons affecter l’énergie que nous produisons. Nous sensibilisons nos clients à ces enjeux, mais ils nous répondent que tant que c’est autorisé, ils y vont. C’est donc au régulateur de prendre ses responsabilités. Mais compte tenu des effets rebond qui vont s’appliquer à l’IA, les désillusions seront à la hauteur de nos illusions. Le bilan des pertes sera beaucoup plus important que le bilan des gains apportés par l’IA », conclut-il.
Et la consommation d’eau ?
L’analyse des impacts environnementaux de l’intelligence artificielle se concentre de prime abord sur les émissions de CO2. Mais la démocratisation rapide de l’IA générative a également remis sur le devant de la scène la problématique de la préservation de l’eau, une ressource amenée à être de plus en plus sous pression. Les CPU et GPU (processeurs et cartes graphiques) utilisés pour faire fonctionner les IA sont en effet refroidis à l’eau. En 2023, le rapport environnemental de Microsoft indique ainsi que la consommation d’eau des centres de données a augmenté de plus d’un tiers entre 2021 et 2022. Sur la même période, Google estime sa propre augmentation à environ 20%.
De son côté, l'université de Californie a calculé que la demande en matière d’IA pourrait augmenter l’extraction d’eau de surface ou souterraine de 4,2 à 6,6 milliards de mètres cubes à horizon 2027. Selon l’université, il s’agit déjà de la moitié de ce que consomme un pays comme le Royaume-Uni annuellement.

Quel impact environnemental pour l’IA générative




